Frequenzbezogene Klangbearbeitung
Filter
Filter bieten die Möglichkeit, den Frequenzgang bzw. die Klangfarbe von Audiosignalen zu beeinflussen. Sie gehören zu den grundlegenden Bearbeitungstechniken jeder Audioproduktion.
Bezeichnungen wie Entzerrer, Equalizer (EQ) weisen auf die technische Tradition der Anwendung von Filtern hin. Gründe für eine Frequenzgangkorrektur sind beispielsweise das Vorhandensein tieffrequenten Störschalls (z.B. Trittschall), starkes Rauschen (z.B. bei alten Magnetbändern oder zu gering ausgesteuerten Aufnahmen) oder unerwünschte Resonanzen, verursacht durch ungünstige Aufnahmebedingungen.
Bei der elektronischen Klangerzeugung (Synthesizer) und der phonographischen Reproduktionsmusik (z.B. der DJ-Culture) sind Filter als medienästhetische Werkzeuge elementarer Bestandteil musikalischer Gestaltung.
Filter bieten folgende Parameteränderungen:
Gain
Kennfrequenz (Grenz- Eckfrequenz, Cutoff, Half-Power Point): Einsatzfrequenz des Filters.
Q-Wert (Q, Peak, Resonanz): Verstärkung der Frequenzen nahe der Kennfrequenz, bzw. allgemeiner: Breite der Dämpfung (z.B. bei Band-Filtern). Meistens einstellbar über eigenen Regler.
Flankensteilheit (Güte, „Pol“): Steilheit der Kennlinie. (dB/Oktave). Oftmals auch als „Pol“ angegeben:
1 Pol = 6 dB/Oktave. Meistens einstellbar durch Wahl eines Filtertyps (z.B. 12-Pol-Lowpass vs. 18-Pol-Lowpass)
Beispiele für den Frequenzgang typischer Filter
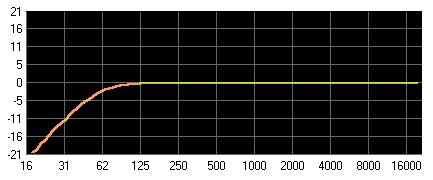
High-Pass oder Low-Cut: Hochpass, Tiefensperre
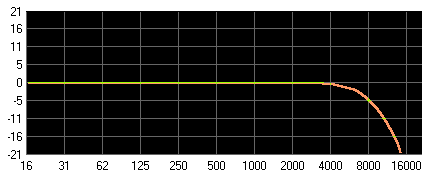
Low-Pass oder High-Cut: Tiefpass, Höhensperre
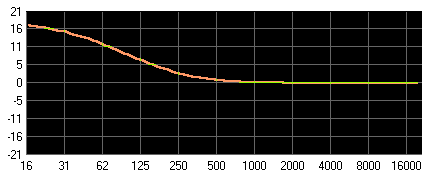
Low-Shelf: Tiefenanhebung
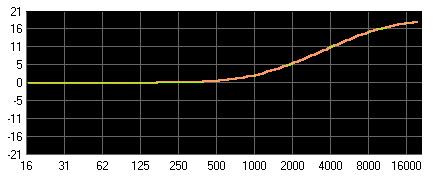
High-Shelf: Höhenanhebung
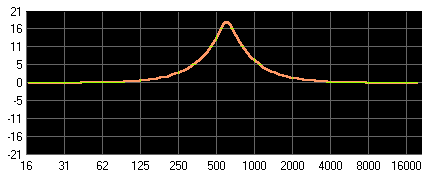
Band-Pass: Bandpass, Präsenzfilter
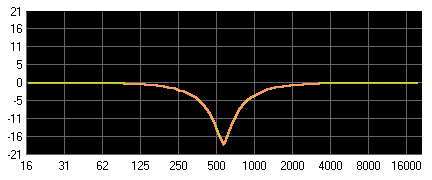
Band-Reject: Bandsperre, Absenzfilter
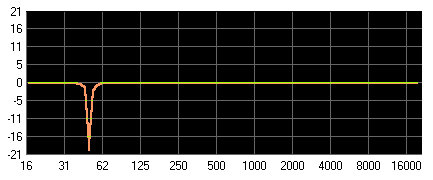
Notch-Filter: Lochfilter, schmalbandige Bandsperre
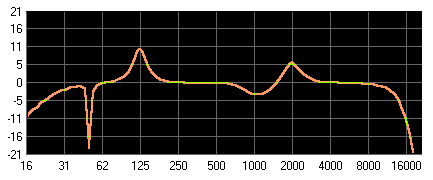
Kombination aus High-Pass, Notch-Filter, Band-Pass, Band-Reject, Band-Pass und Low-Pass
Parametrische Filter
Parametrische Filter bieten, meist anhand von Drehreglern, die Möglichkeit, alle Parameter des Filters (Frequenz, Pegel, Filterbreite) einzeln und unabhängig voneinander einzustellen. Allerdings ist der eingestellte Frequenzgang nicht schnell ablesbar.
Graphische Filter
Graphische Filter bestehen aus einzelnen Schiebereglern, die festen Frequenzbändern mit festen Filterbreiten zugeordnet sind. Nur der Pegel der einzelnen Frequenzbänder ist einstellbar. Der Frequenzgang ist schnell ablesbar.
Paragraphische Filter
Eine Mischform aus parametrischem und graphischem Filter ist der paragraphische Filter. Hier sind, wie beim parametrischen Filter, alle Parameter einzeln und unabhängig voneinander einstellbar. Die Auswirkung auf den Frequenzgang wird jedoch zusätzlich visualisiert.
Dynamische Filter
Die Filtereigenschaften der dynamischen Filter verhalten sich abhängig vom Signalpegel und Signalspektrum. Sie werden z.B. eingesetzt, um Verzerrungen durch Zischlaute bei Sprach/Gesangs-Aufnahmen zu verhindern.
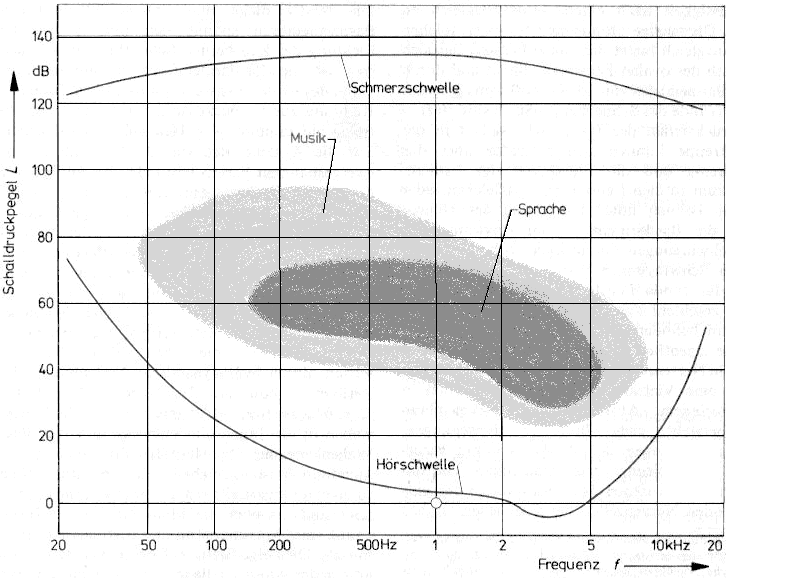
Frequenzbereiche
Subbass: 0 – 25 Hz (Low Cut)
Bass: 25 – 120 Hz (Bass, Bassdrum, Wärme)
Untere Mitten (Low Mid Range): 120 – 350 Hz (Lead Vocals, akkorde p, g, Wärme)
Mitten (Mid Range): 350 – 2000 Hz (nasal)
Obere Mitten (High Mid Range): 2000 – 8000 Hz (Drum-Felle, Sprachverständlichkeit)
Höhen: 8000 – 12000 Hz (Percussion, Hi-Hats, cymbals)
Obere Höhen (Airband): 12000 – 20000 Hz
Tonale Resonanzen
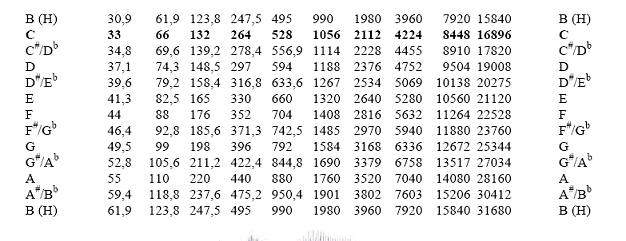
Obertonreihe

Vocoder
Ein Vocoder analysiert den Verlauf der Teilspektren eines Audiosignals (Modulator, Analysesignal) durch eine Filterbank. Die Pegelverläufe dieser isolierten Frequenzbänder steuern die Pegelverläufe der ebenfalls durch eine Filterbank „zerlegten“ Teilspektren eines Trägersignals (Carrier). Somit moduliert der zeitliche Verlauf des Frequenzspektrums des einen Signals den zeitlichen Verlauf des Frequenzspektrums des Anderen. Vocoder werden meist dazu benutzt, um mit einem Sprachsignal ein anderes periodisches, kontinuierliches, obertonreiches Signal zu modulieren. Typisch ist die mit dem Vocoder erzeugte „Roboterstimme“, ein seit den späten 70ern beliebter Effekt in der populären Musik.
Denoiser
Denoiser- oder Noise Reduction-Algorithmen bieten die Möglichkeit, verrauschtes Audiomaterial zu „säubern“.
Hierbei wird eine Stelle ohne Nutzsignal benutzt, um einen sogenannten Noiseprint zu erstellen. Dieser „Fingerabdruck“ des Rauschens dient dann dazu, das Rauschen aus dem gesamten Material zu entfernen. Da ein zu extremer Einsatz zu starken Artefakten führt, läßt sich der Grad der Reduktion einstellen. (Typische Werte sind Rauschreduktionen von 0 dB bis -20 dB). Weitere Parameter sind:
FFT-Size: Größe der Zeitfenster, in die das Signal beim Noiseprint und bei der anschließenden Bearbeitung zerlegt wird. (ca. 8000 ist eine gute Ausgangsgröße)
Lowcut: Durch den Einsatz eines Lowcut-Filters werden die auffälligsten Rauschanteile gefiltert. Der Einsatz wirkt sich allerdings auf das gesamte Material aus. Dynamische Lowcut-Filter lassen (ähnlich einem frequenzabhängigen Noise Gate) das Signal unberührt, wenn die Signalanteile oberhalb der Cutoff-Frequenz einen bestimmten Wert überschreiten.
Autotune / Pitch-Correction
Mit Autotune bzw. Pitch-Correction werden Effekte bezeichnet, die (z.T. in Echtzeit) Tonhöhenbearbeitungen an digitalem Audiomaterial vornehmen, ohne dass dadurch dessen (Makro-)Zeitstruktur verändert wird. Durch Verwendung der Granularsynthese, d.h. der Zerteilung (Analyse) des Audiomaterials in kleine Einheiten (Grains), die anders als bloße Sample-Werte Tonhöheninformation enthalten, können so einzelne Töne oder auch ganze Passagen ohne die Beschleunigung bzw. Verlangsamung transponiert werden.
Die Software Autotune wurde von der Firma Antares 1996 veröffentlicht (zunächst als Plug-In für die Studiosoftware ProTools, 1997 auch als Hardware-Gerät) und ist heute titelgebend für den großen Bereich solcher Pitch-Correction-Effekte, die sich mittlerweile auch in den gängigen DAWs integriert wieder finden (Cubase, Live, Logic, …).
Auch hier sind zwei ästhetische Strategien des Einsatzes von Pitch Correction zu unterscheiden: Subtil angewandt, korrigieren Autotune und co. kleine Ungenauigkeiten in der Intonation und realisieren so technisch einen ›fehlerfreien‹ Vocaltrack. Bei radikaleren Parametereinstellungen (z.B. Toleranzbereich der Korrektur) werden andererseits schnell Artefakte im Signal hörbar. Das Ergebnis – eine technisch überperfekte, roboterhafte Stimme – wurde durch Chers Hit Believe radiotauglich gemacht und später z.B. durch T-Pain oder Kanye West sehr prominent verwendet.
Übrigens: Für genauere Informationen empfehlen wir einen Blick in die Magisterarbeit von Philip von Beesten, hier auf der ((audio))-Seite.